Data Scraping, A complete Beginner Friendly Guide to Become Expert

Web scraping is a technique that allows us to extract data from websites. BeautifulSoup or bs4 is one of the most popular Python libraries that provides us with a way to scrape data from a website. In this blog, we will learn how to get started with BeautifulSoup4 and what are the next steps to follow.
Installing BeautifulSoup4
pip install beautifulsoup4
[Note: If you are getting errors while installing BeautifulSoup4, you can alternatively create a virtual environment in Python. Go to any command line, command prompt, or bash:
python -m venv venv
Then wait a moment for a new folder to be created. If you are on Windows, type:
./venv/scripts/activate
If you are running on Linux or bash, simply type:
source venv/scripts/activate
Then you are good to go. Try installing BeautifulSoup4 again.]
After installing BeautifulSoup4, open any of your favorite code editors and import the following:
from bs4 import BeautifulSoup
import requests
We have imported BeautifulSoup and requests. Now, we can start playing with them.
Let’s start with some basics:
web_response = requests.get("www.samplewebsitename.com")
In the above code snippet, we use the requests.get() method to fetch the website, and the response is stored in the web_response variable. By printing web_response.status_code, we can see that the response code is 200, which translates to a successful request or OK. To view the content of the response, we print web_response.content, which will display the HTML content of the website.
print(web_response.content)
web_response.content returns all the data from the website, but it’s too messy. We use BeautifulSoup to rearrange the data and put it into a more human-readable form, making it easier to extract the correct information.
So, that’s some basics of fetching data from a website. Now let’s get started with bs4:
soup = BeautifulSoup(web_response.content, "html.parser")
The soup variable gets the result of BeautifulSoup. The first parameter is the web_response.content, which is the data of the website, and we use html.parser to tell BeautifulSoup that the data we are providing is HTML content and needs to be parsed.
BeautifulSoup has numerous methods of getting data.
.find() method
soup.find('a')
It will output the first anchor tag which is in the web_response.content. In order for us to extract all the anchor tags <a></a>, we can alternatively use:
web_links = soup.find_all('a')
It will find all the anchor tags and put them in a list.
Extracting the list
for links in web_links:
# required method here
We can simply use for loops to iterate through the list of HTML content with anchor tags and do the required processing and cleaning of data.
.select()
class_select = soup.select(".class_name")
id_select = soup.select("#id_name")
We can also use parent, next_sibling, previous_sibling, as per our requirements.
.get_text()
Here, we are getting the first div of the HTML content and getting the text within it:
soup.find('div').get_text()
We can use | to separate the two texts within an HTML element:
<div>
<p>Hello<span>World</span><p>
</div>
soup.find('div').get_text("|")
Applying the tools to do real scraping
Cocoa Rating Data Analysis and Scraping with bs4
We will try to scrape chocolate data from https://parajulisudip.com.np/bs4/ and answer some questions, such as:
- Which countries produce the highest-rated bars?
- What’s the relationship between cocoa solids percentage and rating?
As usual, let’s start by importing the necessary libraries:
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import pandas as pd
pandas is for creating a DataFrame, and matplotlib is for plotting the dataset and visualizing it later.
web_response = requests.get("https://parajulisudip.com.np/bs4/")
web_response gets the website content in web_response.content, and we will pass it into BeautifulSoup along with html.parser.
soup = BeautifulSoup(web_response.content, "html.parser")
Let’s see what data we need. If we go to the website and inspect it, we would see something like this:
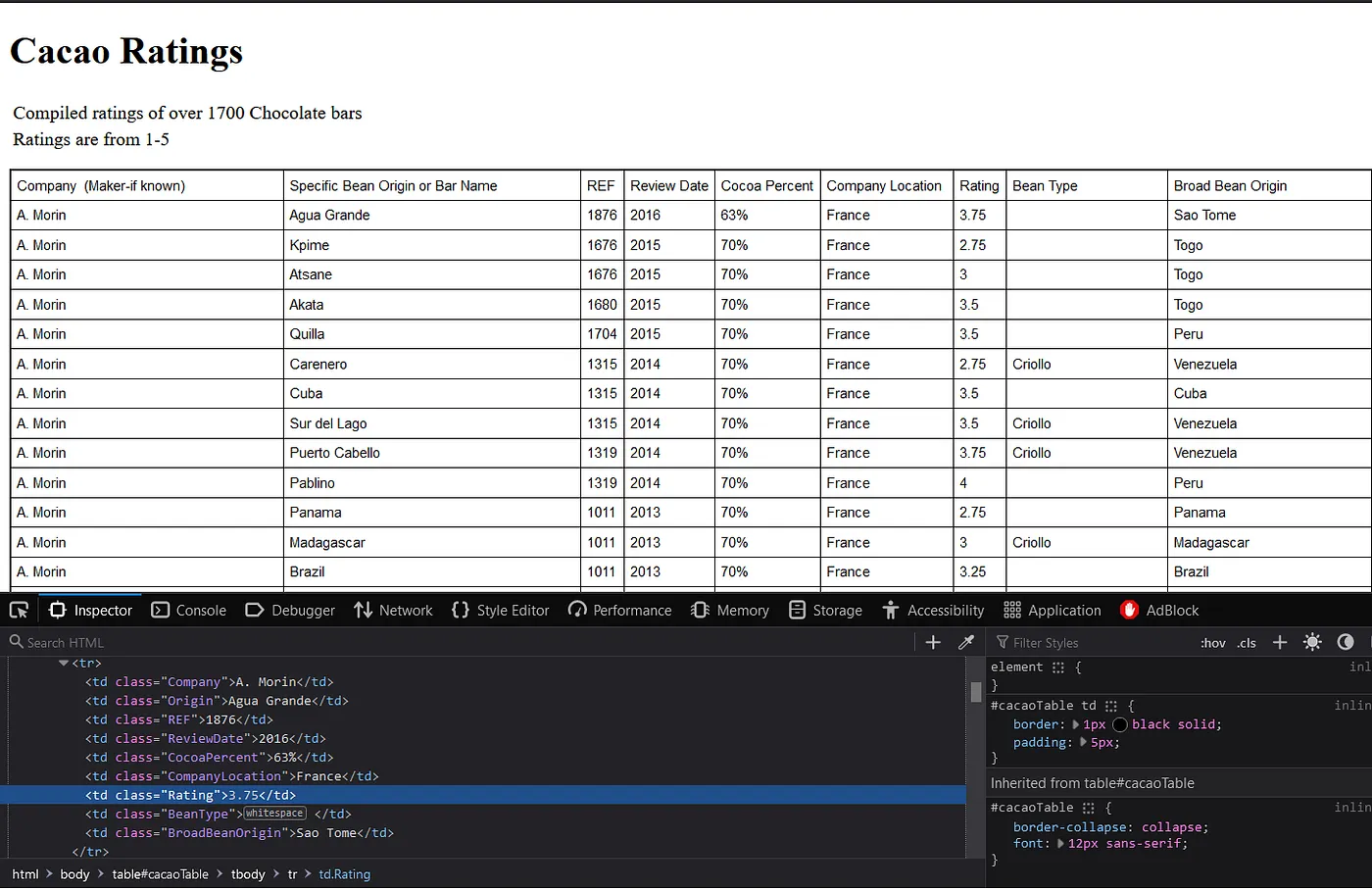
By carefully observing the HTML structure, we can often identify patterns in the data we want to scrape. Armed with our acquired scraping skills, we can extract specific information, such as ratings, from a website. In this case, we’ll focus on extracting ratings from HTML elements enclosed within <td> tags.
ratings = soup.select(".Rating")
rating_list = []
ratings.pop(0)
for rating in ratings:
frating = float(rating.get_text())
rating_list.append(frating)
Plotting the data histogram to view the variation in the ratings with matplotlib
plt.hist(rating_list)
plt.show()
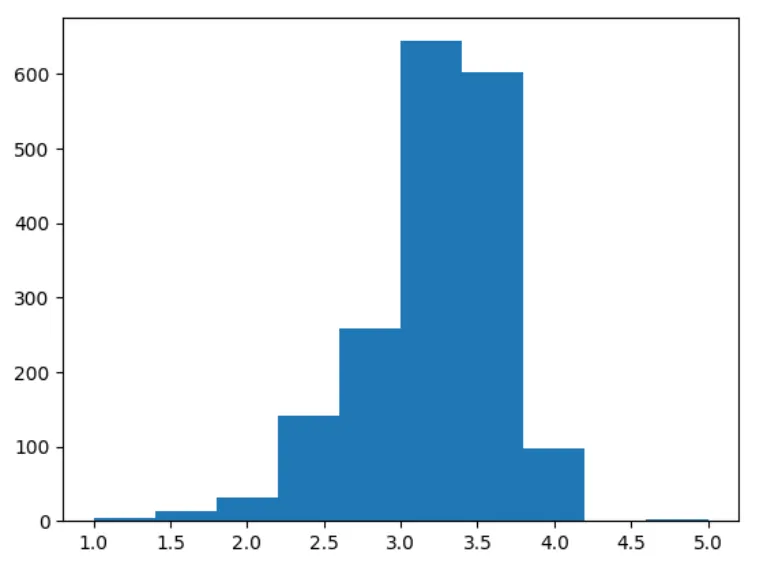
We can clearly see most of the ratings lie between 3 and 4.
Now let’s extract the company and follow the same procedure as above:
company = soup.select(".Company")
company_names = []
for comp in company:
company_names.append(comp.get_text())
company_names.pop(0)
Let’s create a DataFrame (using pandas) of the columns we just made, i.e., company and ratings:
columns = ["Company", "Ratings"]
df = pd.DataFrame(list(zip(company_names, rating_list)), columns=columns)
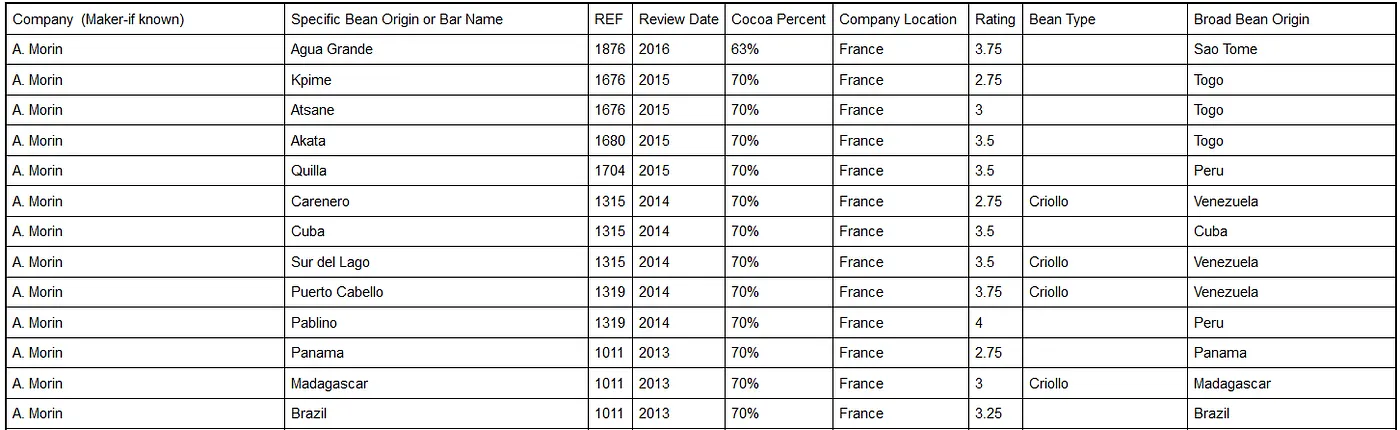
Since we have a single company with different bar names, let’s find out the average and group the companies together and calculate their mean ratings. We can additionally print and view the grouped data:
group_df = df.groupby(['Company'], as_index=False).mean().groupby('Company')['Ratings'].mean()
print(group_df.nlargest(10))

Now, we need to find out which country the company is located in because we know the name of the company with the highest average ratings (i.e., France).

Now, finally, let’s select the class of CocoaPercent. In this case, we have a %, which we have to eliminate and convert the string into float, so we do the following:
cocoa_per = soup.select(".CocoaPercent")
cocoa_per.pop(0)
cocoa_list = []
for cocoa in cocoa_per:
cocoa_str = cocoa.get_text()
cocoa_str = cocoa_str[:-1]
cocoa_list.append(float(cocoa_str))
df["CocoaPercentage"] = cocoa_list
Let’s plot the CocoaPercentage and the ratings given with a scatter plot to see the relationship between them:
plt.scatter(df.CocoaPercentage, df.Ratings)
plt.show()
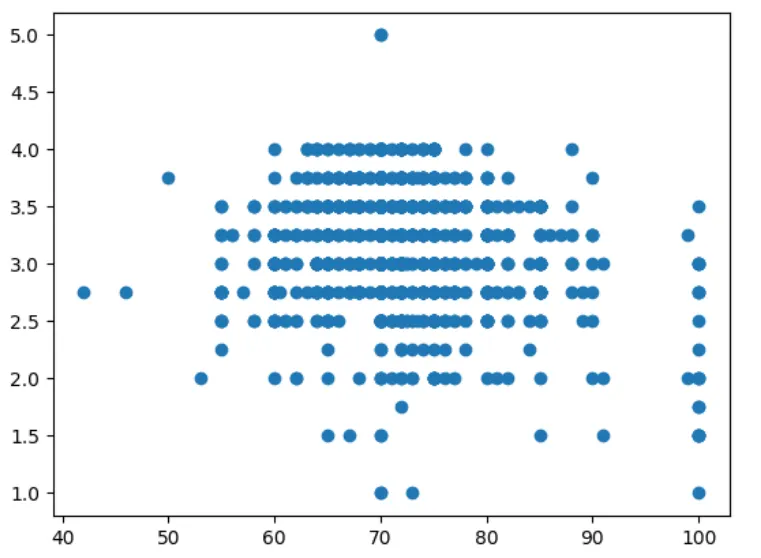
Conclusion
Beautiful Soup 4 is an amazing tool for web scraping in Python. It is easy to use, making it one of the most popular choices among developers. Now that you have some insights about BeautifulSoup and the power of Beautiful Soup 4, you can extract valuable data from websites and leverage it for various applications, such as data analysis, research, etc.
Scraping should always be done responsibly and with respect for the privacy and policies of websites. It is essential to review the guidelines provided by the website you want to scrape.
By adopting a responsible approach to web scraping, you can ensure a positive and mutually beneficial experience for both yourself and the websites you scrape. This is my first blog post—suggestions are highly appreciated. Thank you for reading, and happy scraping!